关于监控
Octopus基于sigs.k8s.io/controller-runtime上搭建,因此某些指标与控制器运行时和client-go相关。 同时github.com/prometheus/client_golang为Go runtime提供了一些指标和过程状态。
指标类别
在 “种类”列中,使用第一个字母代表相应的单词:G - 仪表(Gauge),C - 计数器(Counter),H - 柱状图(Histogram),S - 摘要(Summary)。
Controller Runtime指标对照表
Controller 参数
| 种类 | 名称 | 描述 |
|---|---|---|
| C | controller_runtime_reconcile_total | 每个控制器的reconcile总数 |
| C | controller_runtime_reconcile_errors_total | 每个控制器的reconcile error总数 |
| H | controller_runtime_reconcile_time_seconds | 每个控制器的reconcile时间 |
Webhook 参数
| 种类 | 名称 | 描述 |
|---|---|---|
| H | controller_runtime_webhook_latency_seconds | 处理请求的延迟时间柱状图 |
Kubernetes 客户端指标对照表
Rest 客户端参数
| 种类 | 名称 | 描述 |
|---|---|---|
| C | rest_client_requests_total | HTTP请求的数量,按状态码、方法和主机划分。 |
| H | rest_client_request_latency_seconds | 请求延迟时间,以秒为单位。按动词和URL分类。 |
Workqueue 参数
| 种类 | 名称 | 描述 |
|---|---|---|
| G | workqueue_depth | 工作队列的当前深度 |
| G | workqueue_unfinished_work_seconds | 正在进行中,还没有被work_duration观察到,且正在进行中的工作数量,数值表示卡住的线程数量。可以通过观察这个数值的增加速度来推断卡死线程的数量。 |
| G | workqueue_longest_running_processor_seconds | 工作队列运行时间最长的处理器已经运行了多少秒 |
| C | workqueue_adds_total | 工作队列处理的添加总数 |
| C | workqueue_retries_total | 工作队列处理的重试数量 |
| H | workqueue_queue_duration_seconds | 一个item在被请求之前在工作队列中停留的时间,以秒为单位 |
| H | workqueue_work_duration_seconds | 从工作队列处理一个项目需要多长时间,以秒为单位 |
Prometheus 客户端指标对照表
Go runtime 参数
Running process 参数
| 种类 | 名称 | 描述 |
|---|---|---|
| C | process_cpu_seconds_total | 用户和系统CPU总耗时,单位是秒 |
| G | process_open_fds | 打开的的file descriptors的数量。 |
| G | process_max_fds | file descriptors数量的最大限额 |
| G | process_virtual_memory_bytes | 虚拟内存大小(单位:字节) |
| G | process_virtual_memory_max_bytes | 虚拟内存大小的最大限额(单位:字节) |
| G | process_resident_memory_bytes | 预留内存大小,单位:字节 |
| G | process_start_time_seconds | 进程自unix纪元以来的开始时间(秒) |
Octopus指标对照表
Limb 参数
| 种类 | 名称 | 描述 |
|---|---|---|
| G | limb_connect_connections | 连接适配器当前的连接数量 |
| C | limb_connect_errors_total | 连接适配器时出现的错误总数 |
| C | limb_send_errors_total | 适配器所需发送设备的错误总数 |
| H | limb_send_latency_seconds | 适配器所需发送设备的延迟时间的柱状图 |
监控
默认情况下,指标将在端口 8080上公开 (请参阅brain options和limb options,则可以通过Prometheus进行收集,并通过Grafana进行可视化分析。 Octopus提供了一个ServiceMonitor定义YAML与Prometheus Operator集成用于配置和管理Prometheus实例的工具。
Grafana 仪表板
为方便起见,Octopus提供了Grafana仪表板来可视化展示监视指标。
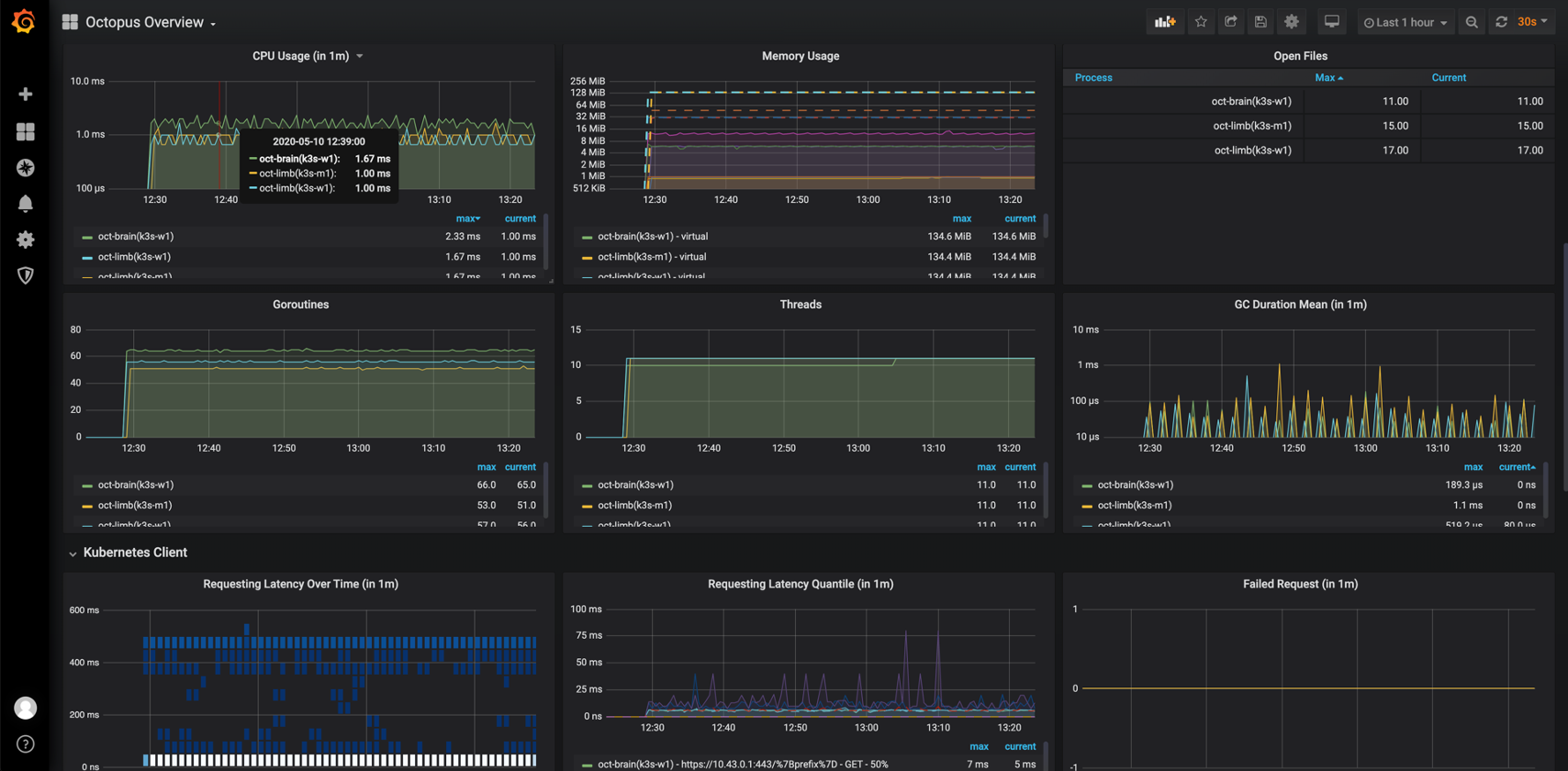
与Prometheus Operator集成
使用prometheus-operator HELM图表,您可以轻松地设置Prometheus Operator来监视Octopus。 以下步骤演示了如何在本地Kubernetes集群上运行Prometheus Operator:
- 使用
cluster-k3d-spinup.sh通过k3d创建本地Kubernetes集群。 - 按照HELM的安装指南安装helm工具,然后使用
helm fetch --untar --untardir /tmp stable/prometheus-operator将prometheus-operator图表移至本地/ tmp目录。 - 从prometheus-operator图表生成部署YAML,如下所示。helm template --namespace octopus-monitoring \--name octopus \--set defaultRules.create=false \--set global.rbac.pspEnabled=false \--set prometheusOperator.admissionWebhooks.patch.enabled=false \--set prometheusOperator.admissionWebhooks.enabled=false \--set prometheusOperator.kubeletService.enabled=false \--set prometheusOperator.tlsProxy.enabled=false \--set prometheusOperator.serviceMonitor.selfMonitor=false \--set alertmanager.enabled=false \--set grafana.defaultDashboardsEnabled=false \--set coreDns.enabled=false \--set kubeApiServer.enabled=false \--set kubeControllerManager.enabled=false \--set kubeEtcd.enabled=false \--set kubeProxy.enabled=false \--set kubeScheduler.enabled=false \--set kubeStateMetrics.enabled=false \--set kubelet.enabled=false \--set nodeExporter.enabled=false \--set prometheus.serviceMonitor.selfMonitor=false \--set prometheus.ingress.enabled=true \--set prometheus.ingress.hosts={localhost} \--set prometheus.ingress.paths={/prometheus} \--set prometheus.ingress.annotations.'traefik\.ingress\.kubernetes\.io\/rewrite-target'=/ \--set prometheus.prometheusSpec.externalUrl=http://localhost/prometheus \--set prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false \--set prometheus.prometheusSpec.podMonitorSelectorNilUsesHelmValues=false \--set prometheus.prometheusSpec.ruleSelectorNilUsesHelmValues=false \--set grafana.adminPassword=admin \--set grafana.rbac.pspUseAppArmor=false \--set grafana.rbac.pspEnabled=false \--set grafana.serviceMonitor.selfMonitor=false \--set grafana.testFramework.enabled=false \--set grafana.ingress.enabled=true \--set grafana.ingress.hosts={localhost} \--set grafana.ingress.path=/grafana \--set grafana.ingress.annotations.'traefik\.ingress\.kubernetes\.io\/rewrite-target'=/ \--set grafana.'grafana\.ini'.server.root_url=http://localhost/grafana \/tmp/prometheus-operator > /tmp/prometheus-operator_all_in_one.yaml
- 通过
kubectl create ns octopus-monitoring创建octopus-monitoring命名空间。 - 通过
kubectl apply -f /tmp/prometheus-operator_all_in_one.yaml将prometheus-operatorall-in-ine部署于本地集群。 - (可选)通过
kubectl apply -f https://raw.githubusercontent.com/cnrancher/octopus/master/deploy/e2e/all_in_one.yaml来部署Octopus说明
国内用户,可以使用以下方法加速安装:
kubectl apply -f http://rancher-mirror.cnrancher.com/octopus/master/deploy/e2e/all_in_one.yaml
:::
- 通过
kubectl apply -f https://raw.githubusercontent.com/cnrancher/octopus/master/deploy/e2e/integrate_with_prometheus_operator.yaml将监视集成部署于本地集群。说明
国内用户,可以使用以下方法加速安装:
kubectl apply -f http://rancher-mirror.cnrancher.com/octopus/master/deploy/e2e/integrate_with_prometheus_operator.yaml
:::
- 访问
http://localhost/prometheus以通过浏览器查看Prometheus Web控制台,或访问http://localhost/grafana以查看Grafana控制台(管理员帐户为admin/admin)。 - (可选)从Grafana控制台导入Octopus概述仪表板。