Monitoring Octopus
Octopus is built on sigs.k8s.io/controller-runtime, so some metrics are related to controller-runtime and client-go. At the same time, github.com/prometheus/client_golang provides some metrics for Go runtime and process state.
Metrics Category
In the "Type" column, use the first letter to represent the corresponding word: G - Gauge, C - Counter, H - Histogram, S - Summary.
Exposing from Controller Runtime
Controller metrics
| Type | Name | Description | Usage |
|---|---|---|---|
| C | controller_runtime_reconcile_total | Total number of reconciliations per controller. | |
| C | controller_runtime_reconcile_errors_total | Total number of reconciliation errors per controller. | |
| H | controller_runtime_reconcile_time_seconds | Length of time per reconciliation per controller. |
Webhook metrics
| Type | Name | Description | Usage |
|---|---|---|---|
| H | controller_runtime_webhook_latency_seconds | Histogram of the latency of processing admission requests. |
Exposing from Kubernetes client
Rest client metrics
| Type | Name | Description | Usage |
|---|---|---|---|
| C | rest_client_requests_total | Number of HTTP requests, partitioned by status code, method, and host. | |
| H | rest_client_request_latency_seconds | Request latency in seconds. Broken down by verb and URL. |
Workqueue metrics
| Type | Name | Description | Usage |
|---|---|---|---|
| G | workqueue_depth | Current depth of workqueue. | |
| G | workqueue_unfinished_work_seconds | How many seconds of work has done that is in progress and hasn't been observed by work_duration. Large values indicate stuck threads. One can deduce the number of stuck threads by observing the rate at which this increases. | |
| G | workqueue_longest_running_processor_seconds | How many seconds has the longest running processor for workqueue been running. | |
| C | workqueue_adds_total | Total number of adds handled by workqueue. | |
| C | workqueue_retries_total | Total number of retries handled by workqueue. | |
| H | workqueue_queue_duration_seconds | How long in seconds an item stays in workqueue before being requested. | |
| H | workqueue_work_duration_seconds | How long in seconds processing an item from workqueue takes. |
Exposing from Prometheus client
Go runtime metrics
| Type | Name | Description | Usage |
|---|---|---|---|
| G | go_goroutines | Number of goroutines that currently exist. | |
| G | go_threads | Number of OS threads created. | |
| G | go_info | Information about the Go environment. | |
| S | go_gc_duration_seconds | A summary of the pause duration of garbage collection cycles. | |
| G | go_memstats_alloc_bytes | Number of bytes allocated and still in use. | |
| C | go_memstats_alloc_bytes_total | Total number of bytes allocated, even if freed. | |
| G | go_memstats_sys_bytes | Number of bytes obtained from system. | |
| C | go_memstats_lookups_total | Total number of pointer lookups. | |
| C | go_memstats_mallocs_total | Total number of mallocs. | |
| C | go_memstats_frees_total | Total number of frees. | |
| G | go_memstats_heap_alloc_bytes | Number of heap bytes allocated and still in use. | |
| G | go_memstats_heap_sys_bytes | Number of heap bytes obtained from system. | |
| G | go_memstats_heap_idle_bytes | Number of heap bytes waiting to be used. | |
| G | go_memstats_heap_inuse_bytes | Number of heap bytes that are in use. | |
| G | go_memstats_heap_released_bytes | Number of heap bytes released to OS. | |
| G | go_memstats_heap_objects | Number of allocated objects. | |
| G | go_memstats_stack_inuse_bytes | Number of bytes in use by the stack allocator. | |
| G | go_memstats_stack_sys_bytes | Number of bytes obtained from system for stack allocator. | |
| G | go_memstats_mspan_inuse_bytes | Number of bytes in use by mspan structures. | |
| G | go_memstats_mspan_sys_bytes | Number of bytes used for mspan structures obtained from system. | |
| G | go_memstats_mcache_inuse_bytes | Number of bytes in use by mcache structures. | |
| G | go_memstats_mcache_sys_bytes | Number of bytes used for mcache structures obtained from system. | |
| G | go_memstats_buck_hash_sys_bytes | Number of bytes used by the profiling bucket hash table. | |
| G | go_memstats_gc_sys_bytes | Number of bytes used for garbage collection system metadata. | |
| G | go_memstats_other_sys_bytes | Number of bytes used for other system allocations. | |
| G | go_memstats_next_gc_bytes | Number of heap bytes when next garbage collection will take place. | |
| G | go_memstats_last_gc_time_seconds | Number of seconds since 1970 of last garbage collection. | |
| G | go_memstats_gc_cpu_fraction | The fraction of this program's available CPU time used by the GC since the program started. |
Running process metrics
| Type | Name | Description | Usage |
|---|---|---|---|
| C | process_cpu_seconds_total | Total user and system CPU time spent in seconds. | |
| G | process_open_fds | Number of open file descriptors. | |
| G | process_max_fds | Maximum number of open file descriptors. | |
| G | process_virtual_memory_bytes | Virtual memory size in bytes. | |
| G | process_virtual_memory_max_bytes | Maximum amount of virtual memory available in bytes. | |
| G | process_resident_memory_bytes | Resident memory size in bytes. | |
| G | process_start_time_seconds | Start time of the process since unix epoch in seconds. |
Exposing from Octopus
Limb metrics
| Type | Name | Description | Usage |
|---|---|---|---|
| G | limb_connect_connections | How many connections are connecting adaptor. | |
| C | limb_connect_errors_total | Total number of connecting adaptor errors. | |
| C | limb_send_errors_total | Total number of errors of sending device desired to adaptor. | |
| H | limb_send_latency_seconds | Histogram of the latency of sending device desired to adaptor. |
Monitor
By default, the metrics will be exposed on port 8080(see brain options and limb options), they can be collected by Prometheus and visually analyzed through Grafana. Octopus provides a ServiceMonitor definition YAML to integrate with Prometheus Operator, which is an easy tool to configure and manage Prometheus instances.
Grafana Dashboard
For convenience, Octopus provides a Grafana Dashboard to visualize the monitoring metrics.
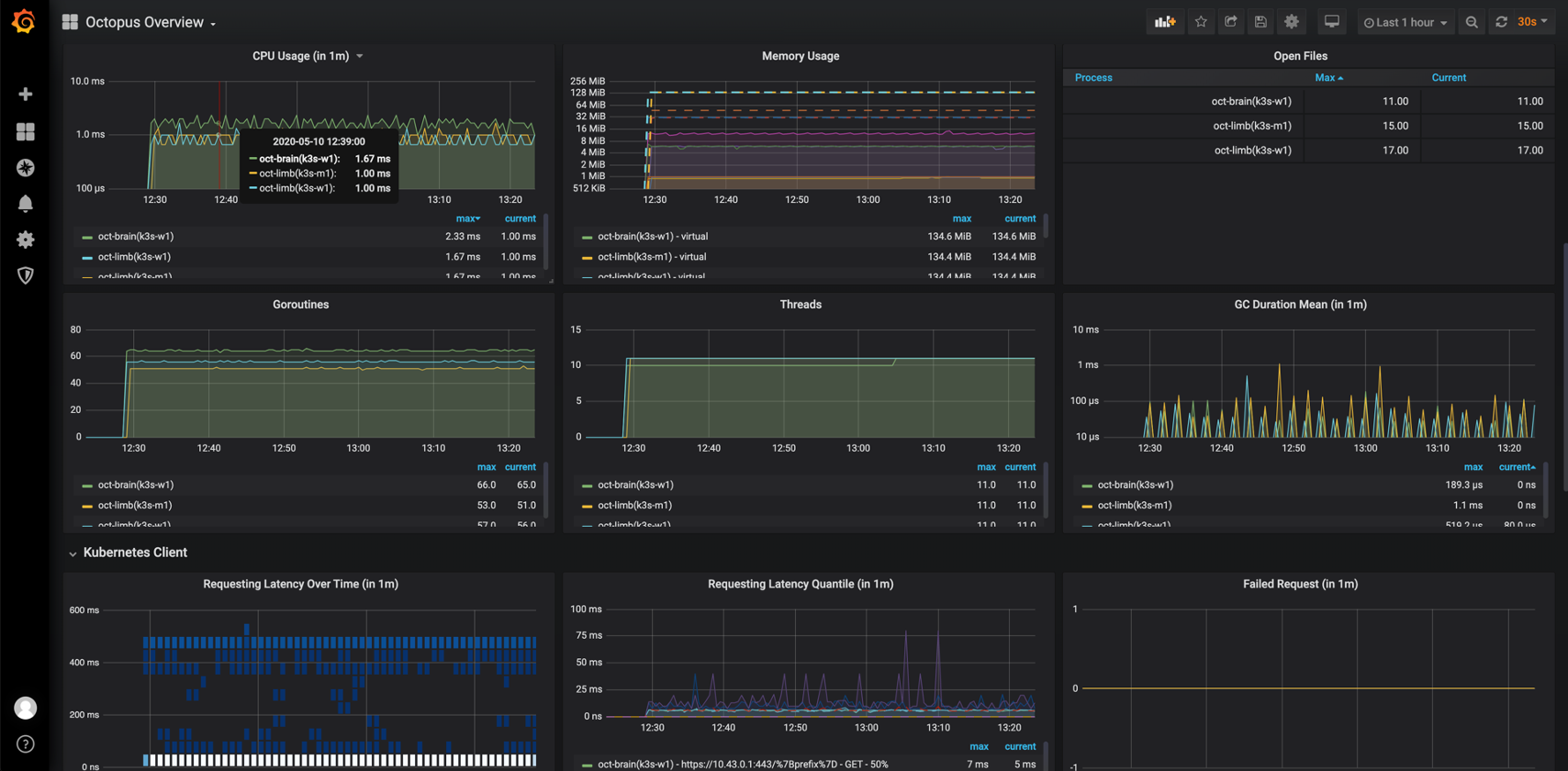 ;
;Integrate with Prometheus Operator
Using prometheus-operator HELM chart, you can easily set up a Prometheus Operator to monitor the Octopus. The following steps demonstrate how to run a Prometheus Operator on a local Kubernetes cluster:
- Use
cluster-k3d-spinup.shto set up a local Kubernetes cluster via k3d. - Follow the installation guide of HELM to install helm tool, and then use
helm fetch --untar --untardir /tmp stable/prometheus-operatorthe prometheus-operator chart to local/tmpdirectory. - Generate a deployment YAML from prometheus-operator chart as below.helm template --namespace octopus-monitoring \--name octopus \--set defaultRules.create=false \--set global.rbac.pspEnabled=false \--set prometheusOperator.admissionWebhooks.patch.enabled=false \--set prometheusOperator.admissionWebhooks.enabled=false \--set prometheusOperator.kubeletService.enabled=false \--set prometheusOperator.tlsProxy.enabled=false \--set prometheusOperator.serviceMonitor.selfMonitor=false \--set alertmanager.enabled=false \--set grafana.defaultDashboardsEnabled=false \--set coreDns.enabled=false \--set kubeApiServer.enabled=false \--set kubeControllerManager.enabled=false \--set kubeEtcd.enabled=false \--set kubeProxy.enabled=false \--set kubeScheduler.enabled=false \--set kubeStateMetrics.enabled=false \--set kubelet.enabled=false \--set nodeExporter.enabled=false \--set prometheus.serviceMonitor.selfMonitor=false \--set prometheus.ingress.enabled=true \--set prometheus.ingress.hosts={localhost} \--set prometheus.ingress.paths={/prometheus} \--set prometheus.ingress.annotations.'traefik\.ingress\.kubernetes\.io\/rewrite-target'=/ \--set prometheus.prometheusSpec.externalUrl=http://localhost/prometheus \--set prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false \--set prometheus.prometheusSpec.podMonitorSelectorNilUsesHelmValues=false \--set prometheus.prometheusSpec.ruleSelectorNilUsesHelmValues=false \--set grafana.adminPassword=admin \--set grafana.rbac.pspUseAppArmor=false \--set grafana.rbac.pspEnabled=false \--set grafana.serviceMonitor.selfMonitor=false \--set grafana.testFramework.enabled=false \--set grafana.ingress.enabled=true \--set grafana.ingress.hosts={localhost} \--set grafana.ingress.path=/grafana \--set grafana.ingress.annotations.'traefik\.ingress\.kubernetes\.io\/rewrite-target'=/ \--set grafana.'grafana\.ini'.server.root_url=http://localhost/grafana \/tmp/prometheus-operator > /tmp/prometheus-operator_all_in_one.yaml
- Create
octopus-monitoringNamespace viakubectl create ns octopus-monitoring. - Apply the prometheus-operator all-in-one deployment into the local cluster via
kubectl apply -f /tmp/prometheus-operator_all_in_one.yaml. - Apply the Octopus all-in-one deployment via
kubectl apply -f https://raw.githubusercontent.com/cnrancher/octopus/master/deploy/e2e/all_in_one.yaml. - Apply the monitoring integration into the local cluster via
kubectl apply -f https://raw.githubusercontent.com/cnrancher/octopus/master/deploy/e2e/integrate_with_prometheus_operator.yaml - Visit
http://localhost/prometheusto view the Prometheus web console through the browser, or visithttp://localhost/grafanato view the Grafana console(the administrator account isadmin/admin). - (Optional) Import the Octopus Overview dashboard from Grafana console.